{kind=link}
前回の投稿(【ワイン画像識別2026】SigLIP2)で予告したように、今回はセマンティックセグメンテーションの見直しを行いました。
セグメンテーションの実装自体の変更に加えて、以前の投稿(2025年はワイン画像識別と共に始まり、そして暮れゆく)内の「2026年の抱負 – ボトル画像を対象とした特徴抽出器」で触れたように、ラベル部分に完全に絞り込むのではなく、ラベル周辺のボトル部分も含めた抽出を行うように変更しました。
これにより、ボトルの色や形状なども特徴抽出の材料になることを期待しています。
エンベディングモデルの学習結果
早速ですが、最終目的であるエンベディングの精度がどのように変わったかを先に見てしまいましょう。
なお、セグメンテーションの方法が変わっただけで、それ以外(特徴抽出器自身や学習に関連するロジックおよびハイパーパラメータ等)の変更はありません。
対象とする元画像も全て前回と同じで、学習時の分類(訓練・検証・テスト)も変わっていません。
以下、前回と今回の結果が比較しやすいように並べて記載してあります。
まずは、いつもの各種指標に関して。
前回同様、全データとテストデータのみの場合のそれぞれで集計してみました。
全データ
| 閾値 | ポジティブ | ネガティブ | 適合率 | 再現率 | F1スコア | Fβスコア | |
| 前回 | 0.19 | 1112 | 1 | 0.9991 | 0.9929 | 0.9960 | 0.9978 |
| 今回 | 0.23 | 1119 | 0 | 1.0000 | 0.9991 | 0.9996 | 0.9998 |
テストデータ
| 閾値 | ポジティブ | ネガティブ | 適合率 | 再現率 | F1スコア | Fβスコア | |
| 前回 | 0.19 | 107 | 0 | 1.0000 | 0.9727 | 0.9862 | 0.9944 |
| 今回 | 0.23 | 109 | 0 | 1.0000 | 0.9909 | 0.9954 | 0.9982 |
前回は1つの特殊なネガティブが問題となっていましたが、今回は綺麗に閾値=0.23で適合率100%を実現できています。
再現率も高いですが、こちらは率に着目するよりも、閾値を超える(ハード)ポジティブが1つのみであったという事実が重要です。
ポジティブ・ネガティブの分布状況に関しても整理してみました。
ポジティブ
| 平均値 | 中央値 | 最小値 | 最大値 | 標準偏差 | |
| 前回 | 0.0250 | 0.0162 | 0.0023 | 0.4831 | 0.0353 |
| 今回 | 0.0222 | 0.0161 | 0.0027 | 0.2643 | 0.0219 |
ネガティブ
| 平均値 | 中央値 | 最小値 | 最大値 | 標準偏差 | |
| 前回 | 0.9987 | 1.0028 | 0.1101 | 1.3201 | 0.0740 |
| 今回 | 1.0033 | 1.0067 | 0.2393 | 1.3203 | 0.0737 |
ポジティブの最大値、ネガティブの最小値ともに大幅に改善しており、特にポジティブにおいて標準偏差が前回の62%程度に小さくなっているので、同じラベルを写した画像に関するエンベディング結果(ベクトル)がより密集するようになったと言えます。
では、今回の結果で唯一問題となるハードポジティブが何かと言うと、例のアレです。
比較のために、上に前回の結果、下に今回の結果を並べてみました。
 |  | 0.3013 |
 |  | 0.2643 |
若干見にくいですが、前回の画像は無理やりラベル部分の境界を引いている印象があるのに対し、今回の画像ではボトル部分で境界を引いているので、ラベルの形状に不自然さがありません。
その辺が良かったのか、前回は閾値=0.19に対して0.3013の距離があったものが、今回は閾値=0.23に対して0.2643と、かなり近づいてきています。
一方で、今回の最もハードなネガティブは以下でした。
 |  | 0.2393 |
前回の実質的最ハードネガティブと似ていますが、左の方が前回のものとは異なっています。
むしろ今回の組み合わせの方が(細かいですが)色の違いなどもあって、前回の組み合わせよりも見分けるヒントは多そうなのですが、この辺の判断基準は良く分かりません(AIあるある)。
せっかくですので、前回のハードサンプルに関する距離がどのように変化したかに関しても見てみましょう。
まずはハードポジティブに関して。
例によって、上に前回、下に今回の情報を並べてあります。
 |  | 0.4831 |
 |  | 0.0518 |
この例は、ボトル部分での切り抜きが露骨に分かりますね。
加えて言えば、ボトルの境界の判定が、かなり雑です。
それでも、距離は0.4831から0.0518まで大きく近づきました。
何が良かったんでしょう?
次はハードネガティブに関して。
1つ目は、前回の状況(ラベルのみの切り出し)では根本的に区別が困難な、つまりサンプルとして不適切な例と判断したものです。
|  | 0.1101 |
|  | 0.8665 |
これはボトル部分を含むことの重要性が良くわかるケースです。
これだけ色の違いがあれば、距離が0.1101から0.8665まで変化するのも頷けます。
もう一つ、前回の実質的最ハードネガティブに関しても見てみましょう。
 |  | 0.1991 |
 |  | 0.3304 |
こちらは、人間の目で見た印象としては大きく変わりませんが、それでも距離が0.1991から0.3304まで大きくなっています。
この辺も謎です。
上記のように、ケースによって印象が違いますが、全般的にボトルまで含めたことで精度が向上したことは間違いありません。
しかし、露骨に色の違いが分かるようになったケースを除いて、何が良かったのか分からないケースも多いです。
この辺をAI先生に聞いてみました。
入力画像の変更点は「ラベル周辺のボトル表面が可視化されたこと」のみである。以下、データから読み取れる複数の要因を分析する。
1 ボトル表面の色・質感が識別補助特徴として機能
ラベルの文字・図柄が類似するワインペアであっても、ボトルの色(緑、茶、透明など)や表面の質感・反射が異なることは珍しくない。ボトル表面が入力画像に含まれることで、ラベル単体では判別困難なペアに対して追加の識別手がかりが提供された。
2 ラベル境界の文脈情報の回復
前回の方式ではラベル輪郭に沿って厳密に黒塗りされていたため、ラベルの端部はセグメンテーション境界の不正確さの影響を直接受けていた。今回の方式ではラベル周辺にボトル表面が自然に存在するため、ラベル端部の特徴が境界アーティファクトなしに保持される。
3 人工的な黒塗り境界がもたらすアーティファクトの解消
ラベル形状に沿った複雑な黒塗り境界は、画像中に「自然界に存在しない急激なコントラスト変化」を大量に生成する。SigLIP2 のような事前学習済み Vision Transformer は自然画像で事前学習されているため、このようなアーティファクトに対して事前学習で得た特徴表現が適切に機能しない可能性がある。1は当初から想定していた内容です。
2に関しては、前回のセグメンテーションではラベルの境界を正確に判別できず、結果として切り出されたラベル部分の境界が不自然な形状(本来の境界とは適合しない凸凹あり)となっていたことが悪影響を及ぼしていた、と言ったところでしょうか。
今回はボトルで境界を引くことで、ラベルの境界が自然な(本来の)形状になったため精度が向上したと言うことのようです。
この分析内容は、最初に例示した、今回唯一のハードネガティブの状況からも納得できます。
3に関しては、ベースモデルが学習してきた画像群になかったような不自然な特徴を含む画像は学習や予測の精度を悪化させる要因になると言うことのようです。
これに関しては、以前学習用データの水増し策を考えていた段階でも指摘されたことで、実際のラベル画像を集めるのは大変なのでラベルっぽい画像を捏造しようとしたところ、同様の注意を受けました。
なお、上記分析が正しいのであれば、ボトルの背景も黒塗りにせず元画像の背景をそのまま残した方が良いのではないかとも考えたのですが、必ずしもそうではないようです。
背景の様々な写り込みが特徴量に与える影響はやはり侮れないようで、メリット・デメリット両面が考えられるものの、現状のようなボトルの背景を黒塗りとする戦略が、少なくとも現時点の予測としては最もバランスの良い方式ではないと言うのがAI先生の見解です。
セグメンテーションモデル刷新
では、改めてセグメンテーションモデルに関する改修内容を紹介します。
PyTorch化
以前はTensorflowを使用していましたが、今後はPyTorchを使用するようにします。
これは以前の投稿(【ワイン画像識別2026】今更ながらPyTorch)でも記載したようにモデルの選択肢の豊富さや、Mac(Apple Silicon)との親和性を考慮したためです。
アーキテクチャの変更(自製U-Net → DeepLabV3+)
セグメンテーションモデルはエンコーダとデコーダのセットで構成され、エンコーダが入力画像を特徴量に変換し、デコーダが前述の特徴量を元画像の解像度に復元しながらピクセル単位の意味を各座標に投影します。
以前の投稿(ラベル画像のトリミング(2))で解説したように、今までのセグメンテーションモデルの構造は「U-Net」というものでしたが、これは大雑把に言うと以下の特徴を持つエンコーダ・デコーダで構成されたものでした。
- エンコーダとデコーダが同じ解像度・階層数で構成されている(対称性)
- エンコーダの各階層から全く同じ解像度を持つデコーダの階層へ、特徴マップを直接コピーして結合(Concatenate)することで物体の境界線(エッジ)を極めて正確に復元する(スキップ接続)
実は、上記特徴は主にデコーダ側に関わるものであり、「エンコーダが抽出した特徴量を、どうやって元の画像のサイズに復元し、ピクセルごとの分類に繋げるか」というデコーダのアルゴリズムこそがセグメンテーションモデルの本質であると言えます。
一方で、エンコーダはあくまで特徴抽出器であり、これはエンベディングでも扱ってきたResNet50やEfficientNetV2Lなどと同じで、あくまで汎用的な機能に過ぎません。
従来のU-Net構造の実装も、正確に表現するのであれば「自製のU-Net型デコーダに対して自製のエンコーダを組み合わせたもの」と言うべきものだったようです。
上記のように、セグメンテーションモデルのアーキテクチャと言った場合、実質的にはデコーダの構造と言って良いようですが、今回そこを従来の(自製)U-Netから「DeepLabV3+」なるものに変更しました。
現在のアノテーションはLabelMeを使用して手動で行なったものなので、境界が結構いい加減ですが、今後も含めてアノテーションの精度を上げることは難しそうです。
その前提でも良い精度を出せそうなものと言うことで、改めてAI先生に推薦してもらったのがDeepLabV3+でした。
エンコーダの変更(自製 → EfficientNetV2-S)
前述したように、エンコーダはセグメンテーションに特化したものである必要はなく、あくまで一般的な特徴抽出器として今回の用途に適したものを採用すれば良いようです。
そこを自製して一から学習させていたのですから、以前は随分無駄なことをやっていたような気がします。
と言うことで、改めてAI先生に推薦してもらったのが「EfficientNetV2-S」でした。
見ての通り、EfficientNetV2シリーズの1つですね。
他にもResNetシリーズやConvNeXtなど聞いたことがあるようなモデルが候補に上がりましたが、開発環境のスペックや学習用データ量などの事情を考慮しつつ、期待できる精度とのバランスで選ばれたのがEfficientNetV2-Sだったようです。
なお、今回のセグメンテーションモデルの学習においてはエンコーダは学習対象とはせず、既存の性能のまま使用します。
学習対象となるのはデコーダのみです。
segmentation_models_pytorchによるモデル構築
前述したエンコーダ・デコーダを組み合わせてセグメンテーションモデルを構成する必要があるのですが、その操作を簡単に行うための仕組みが「segmentation_models_pytorch(smp)」です。
具体的には以下のように記述するだけで、EfficientNetV2-SとDeepLabV3+を組み合わせたセグメンテーションモデルが構築できるようです。
model = smp.DeepLabV3Plus(
encoder_name="tu-tf_efficientnetv2_s",
encoder_weights="imagenet",
in_channels=3,
classes=1,
activation=None,
)蛇足ながら、Tensorflowでは上記のように簡単な記法はないようです。
PyTorch万歳。
ボトル部分のアノテーション
最初に書いたように、今回は従来のようにラベル部分だけを切り出すのではなく、ボトル部分も含めた切り出しを行います。
以前の投稿(画像検索の精度確認(5))にもあるように、rembgを使ってある程度はボトル部分の抽出(背景を黒く塗りつぶす)は可能なのですが、そもそもrembgはボトルのみを被写体として認識するように調整された機能ではないため、ラベル部分が大きく写っているような画像ではラベルの絵柄に反応してしまい、期待したような結果が得られない可能性があります。
やはり、ボトル用セグメンテーションモデルを自力で生成する必要がありそうです。
セグメンテーションモデルの学習にはアノテーションが必要であり、ラベルに関してはLabelMeを使用して手作業で実施したのですが、同じ作業をボトルに対しても行うのは少々面倒です。
ボトルの境界はラベルの境界と比較してシンプルですので、何とか自動でアノテーションを実行できないものかとAI先生に相談したところ、提案されたのが「Grounding DINO + SAM(Segment Anything Model)」方式です。
Grounding DINO は、指定したキーワード(例えば “wine bottle”)に対して、入力画像内からキーワードに該当する部分を特定し、そこを囲む矩形を生成します。
SAM は、上記矩形で指定された箇所の対象物(大雑把には、「矩形の中心付近にある、境界線で囲まれた連続した領域」という理解で良いようですが)を抽出するマスクを生成します。
この組み合わせにより、ワインボトルが撮影された画像からボトル部分を示すマスクが生成できる訳です。
なお、上記で Grounding DINO + SAM によりボトル部分のマスク画像が生成できるのであれば、改めて同マスク画像を生成するためのセグメンテーションモデルは必要ないのでは?と言う疑問も生じるのですが、実は性能差が大きいです。
実際に計測してみたところ、 Grounding DINO + SAM では1枚の画像(1200×1200)の処理に3秒弱程度要するのに対し、セグメンテーションモデルでは0.05秒前後で処理できています。
よって、Grounding DINO + SAM はアノテーションに限定した機能として使用することにします。
Grounding DINO + SAM により生成されたマスクは以下の通りです。
比較のため、元画像と並べてあります。
 |  |
 |  |
 | 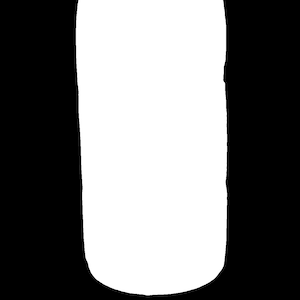 |
遠中近どの距離で撮影したものでも、そこそこ安定的なマスク画像が生成できているようです。
なお、実際に試した383枚の画像中、1つだけGrounding DINOによるボトル部分の特定ができないものがありました。
それが以下です。
 |
似た印象の画像は他にもあったのですが、なぜ上記のみ失敗したのかは謎です。
今回はあくまで学習に使用するマスク画像の生成が目的なので、上記は学習対象から除外して作業を進めることにします。
セグメンテーションモデルの学習結果
ボトル用のマスク画像も用意できましたし、ラベル用のマスク画像は以前からあるものを引き続き使用すれば良いので、これでボトル用・ラベル用それぞれのセグメンテーションモデルを生成するための準備が整いました。
蛇足ながら、セグメンテーションに際しては1つの対象しか指定できない訳ではなく、ラベル・ボトル・それ以外の3クラスに分別するようなセグメンテーションも可能です。
ただし、その場合は今のやり方を色々と変更しなければならないので、まずは単純に二値化する今までの流儀を踏襲して、ラベル用とボトル用のセグメンテーションモデルを別々に生成することにします。
で、学習結果ですが、まずは以前のようにloss, val_lossの推移をグラフ化してみました。
損失関数は以前と同じくDice損失です。
左がボトル用、右がラベル用です。
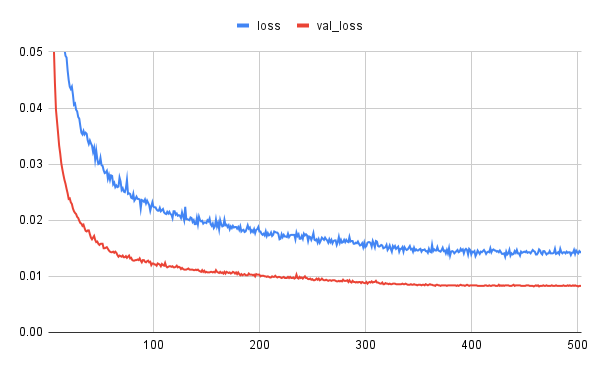
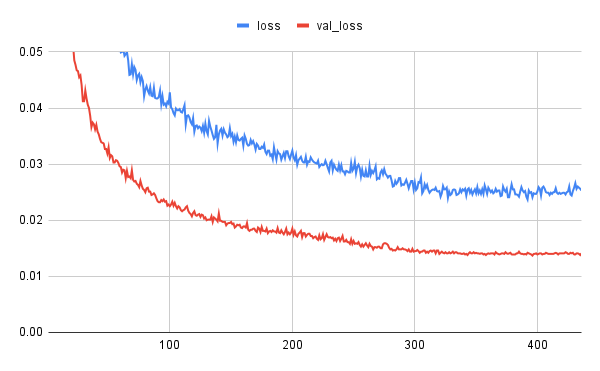
自製U-Netと比較して、減衰状況が安定しています。
特徴抽出に既成エンコーダをそのまま使用している効果でしょうか。
lossよりもval_lossの方が良い値になっていますが、loss(訓練時)の方はデータ拡張により難易度が上がっていることが影響していると推測します。
ボトル用の方がラベル用よりも値が小さく、減衰速度も速いですし、その後も長く学習が継続しています。
これは、ボトルの方が形状(境界)がシンプルであり、より学習の成果が出やすかったものと推測します。
上記のように学習を行なったボトル用・ラベル用のセグメンテーションモデルですが、これらは個別に使用するのではなく、組み合わせて使用します。
具体的には以下の通り。
- ボトル用で生成したマスクにより元画像からボトルの背景を黒く塗り潰した画像を生成
- ラベル用で生成したマスクにより元画像におけるラベルの位置を特定
- 1で生成した画像から2の情報に従ってラベル部分が所定のサイズで大写しになるようにトリミング&リサイズ
上記結果、以前と同等の構図・解像度で、かつラベル周辺のボトル部分までを含む(それ以外の部分は黒く塗り潰した)画像が生成されます。
実際に生成された画像に関しては、先の「エンベディングモデルの学習結果」で紹介済みですが、ここでは若干問題がありそうなケースを追加で紹介します。
 |  |
左はラベルの位置を正確に取得できなかった模様で、ラベルの上の部分が期待されるよりも大きく含まれてしまっています(相対的にラベル部分の面積が小さくなっている)。
右はボトルの境界が正確に判別できておらず、右側に尻尾のように塗り漏れ部分が残ってしまっています(実は、この部分にはボトルの影が写っています)。
上記2つのパターンは複数の画像に見られました。
ただ、上記ケースがエンベディングに与えた影響は、ほとんど確認されていません。
上記のようなイレギュラーな状況は同じラベルを写した他の画像との距離に影響を与えそうに思うのですが、実際の数値を見ると、正常な画像同士の距離と概ね同レベルの値になっています。
この程度のアーティファクト(先にも出てきましたが、加工の不備で生じたゴミ情報をそのようの呼称するようです)ではSigLIP2の特徴抽出には影響を与えないと言うことなんでしょうかね。
いずれにしても、現状程度のセグメンテーションができれば、大きな支障なくワインの識別が実施できそうです。
まとめ
今回は、エンベディングの精度向上に貢献しそうなセグメンテーションの見直しということで以下の2つを実施しました。
- セグメンテーションモデル自体の刷新
- 切り出す範囲の見直し(周辺のボトル部分を対象に追加)
見た限り、1によってセグメンテーション結果(エンベディングの入力画像)の質が向上したということはなさそうです。
境界のジャギーの入り方も以前の状況から改善しているようには見えませんし、前述したようにアーティファクトも点々と発生しています。
ただ、上記のような「切り出し部分の境界の正確さ」は、主目的であるエンベディングの精度向上には良くも悪くもあまり影響しないようです。
言い換えれば、この観点で現状以上の質を追求することは、あまり意味がないと言うことになります。
処理内容はすっきりしましたし、特にエンコーダ・デコーダ部分は簡単に切り替えられそうになりましたで、今後の保守・拡張性を向上させると言う副産物的成果はあったと言うことで結果オーライとしておきます。
一方で、2の効果は十分にあったようです。
ラベル部分(紙)とは異なり、ボトル部分(ガラス)には周辺の様子が結構映り込むので、それらがエンベディング時のノイズとなることを警戒していたのですが、今のところ明確な悪影響は確認されていません。
デメリットがない(小さい)のであれば、識別に必要な情報(ヒント)は多い方が良いと考えるのが自然です。
また、先に示したAI先生の分析(推測)結果を信じれば、切り出し範囲をボトルまで広げたことで重要なラベル周辺のアーティファクトが軽減したこともエンベディングの精度向上に貢献しているようですし。
ワイン画像識別として追求すべき「セグメンテーションの要件」としては、こんなところでしょうかね。
これで、ある程度満足できる精度を持った「セグメンテーション+エンベディング+ベクトル検索」が実施可能になったので、次回はこれらを実際に組み合わせた動作に関して確認してみたいと思います。