{kind=link}
前回の投稿(ラベル画像のエンベディング)において、「やはりラベルの識別に特化したエンベディング方法が必要な気がします」と結論づけたので、その辺をGemini先生に相談したところ、ファインチューニングを試してみるようアドバイスを受けました。
と言うことで、今回はResNet50をラベル画像識別用にファインチューニングしてみます。
当然ながら、実装はGemini先生依存です。
関連パッケージインストール
ファインチューニングに関しても、新たなPythonのvenv環境を構築しておきます。
必要なパッケージは以下のようです。
# pip install opencv-python tensorflow tensorflow-metal scikit-learn目新しいものと言えば「scikit-learn」ですが、今回は同パッケージの「train_test_split」なる関数のみ使用しています。
これは、NumPy配列やリストで管理されているデータを学習用と評価用に簡単に分けられる機能です。
ただ、同様のことはセマンティックセグメンテーションに関する学習時にも実施しており、その時は上記関数は使用せず、独自に分別を行っていました。
Gemini先生も大分気まぐれなようです。
データの準備
ファインチューニングに使用するワインラベルの画像データに関しては、「ラベル画像のトリミング(4)」で用意した200点の画像を使用します。
なお、本学習においても背景等の余計な情報は無い方が良いようなので、上記投稿時に併せて生成したマスク画像を使用して、ラベル部分以外を黒く塗りつぶしておきます。
なお、データ数としては(いつもの事ならが)心許ないようですが、その辺は例によってデータ拡張で水増し予定です。
ファインチューニングの実装
以下に実装内容を紹介していきます。
全体としては相応に量があるので、説明もかなり端折ります。
内容に関して気になる方は、Gemini先生をはじめとするLLM諸先生方に該当箇所をコピペして、聞いてください。
懇切丁寧な解説が得られると思います(実装も解説も他人任せ)。
画像の読み込みとデータ拡張
import tensorflow as tf
def augment_image(image, augmentation_layers):
image = tf.image.random_brightness(image, max_delta=0.2)
image = tf.image.random_contrast(image, lower=0.8, upper=1.2)
image = tf.image.random_saturation(image, lower=0.8, upper=1.2)
for layer in augmentation_layers:
image = layer(image)
noise = tf.random.normal(shape=tf.shape(image), mean=0.0, stddev=10.0, dtype=tf.float32)
image = image + noise
image = tf.clip_by_value(image, 0.0, 255.0)
return image
def preprocess_image(image_path, image_size):
image_bytes = tf.io.read_file(image_path)
image = tf.image.decode_jpeg(image_bytes, channels=3)
image = tf.image.convert_image_dtype(image, tf.float32) * 255.0
image = tf.image.resize(image, image_size)
image = tf.keras.applications.resnet50.preprocess_input(image)
return image
def train_preprocess(image_path, image_size, augmentation_layers):
image = preprocess_image(image_path, image_size)
image = augment_image(image, augmentation_layers)
return image
def val_preprocess(image_path, image_size):
image = preprocess_image(image_path, image_size)
return image外部から使用される関数はtrain_preprocess(学習用データの事前処理)とval_preprocess(評価用データの事前処理)の2つです。
両者の違いはデータ拡張(augment_image)を実行するかどうかのみです。
augment_imageでは各種変換を行っていますが、一部に関しては、外部で用意した変換処理(augmentation_layers)を使用しています。
トリプレット生成
ここで言う「トリプレット(3個1セット)」とはアンカー、ポジティブ、ネガティブの3つの画像パスのセットを意味します。
アンカーとは比較の基準となる画像、ポジティブはアンカーの仲間とみなしたい画像、ネガティブはアンカーの仲間に含めたくない画像であり、今回に関して言えば、ポジティブは同じワインラベルを写した別画像、ネガティブは別のワインラベルを写した画像、と言うことになります。
import random
def get_triplet(label_to_paths, available_labels):
anchor_label = random.choice(available_labels)
anchor_path = random.choice(label_to_paths[anchor_label])
positive_path = anchor_path
negative_label = random.choice([l for l in available_labels if l != anchor_label])
negative_path = random.choice(label_to_paths[negative_label])
return anchor_path, positive_path, negative_path
def triplet_generator(label_to_paths_subset, subset_labels):
while True:
yield get_triplet(label_to_paths_subset, subset_labels)ここでも、外部から呼ばれるのはtriplet_generatorのみです。
get_tripletではアンカー、ポジティブ、ネガティブの3つの画像のパスを返しますが、元情報として、label_to_paths(ファイル名をキーとし、パスを値とする辞書)とavailable_labels(ファイル名のリスト)を使用しています。
available_labelsからランダムに1つファイル名を取得し、対応するパスをアンカーとポジティブの両方のパスとします。
一方で、ネガティブに関しては上記とは別のファイル名に対応するパスを採用しています。
モデルの生成
今回の主目的である、ファインチューニングの対象となるモデルを生成します。
import tensorflow as tf
from tensorflow import keras
def build_encoder(image_size):
input_shape=(image_size[0], image_size[1], 3)
base_model = tf.keras.applications.ResNet50(
input_shape=input_shape,
include_top=False,
weights='imagenet',
pooling='avg'
)
for layer in base_model.layers:
layer.trainable = False
set_trainable = False
for layer in base_model.layers:
if layer.name == 'conv5_block1_out':
set_trainable = True
if set_trainable:
layer.trainable = True
inputs = tf.keras.Input(shape=input_shape)
outputs = base_model(inputs)
outputs = keras.layers.UnitNormalization(axis=1)(outputs)
encoder = tf.keras.Model(inputs, outputs, name="encoder")
return encoderResNet50のモデルを取得した後に、全体の層を一旦訓練不可とし、その後に「conv5_block1_out」以降の層のみ訓練可能に変更しています。
ここが今回の学習のミソで、Gemini先生曰く、
ResNetのような事前学習済みモデルでは、初期の層(Stage 1-4)は一般的な画像特徴(エッジ、テクスチャ、単純な形状など)を学習しており、これらは多くの画像認識タスクで再利用可能です。最後のステージ(Stage 5)はよりタスク固有の特徴を学習するため、ここからファインチューニングを開始することで、ImageNetで学習した汎用的な知識を保持しつつ、ワインラベルという特定のタスクにモデルを適応させることができます。とのことです。
つまり、今回の目的である「ワインラベルの識別」に対して効率の良い学習が行えるよう、ResNet50の既存能力をそのまま活かせる部分は触らずに、必要な部分だけ改変するように設定している訳です。
学習用クラスの定義
前述のモデルに対して学習を実行するためのクラスです。
tf.keras.Modelを継承していることで、Kerasの学習に関するメソッドであるcompileやfitが使えるようになります。
import tensorflow as tf
class TripletModel(tf.keras.Model):
def __init__(self, encoder, margin=1.0):
super().__init__()
self.encoder = encoder
self.margin = margin
self.train_loss_tracker = tf.keras.metrics.Mean(name="loss")
self.val_loss_tracker = tf.keras.metrics.Mean(name="val_loss")
def call(self, inputs):
anchor, positive, negative = inputs
anchor_embedding = self.encoder(anchor)
positive_embedding = self.encoder(positive)
negative_embedding = self.encoder(negative)
return anchor_embedding, positive_embedding, negative_embedding
@property
def metrics(self):
return [self.train_loss_tracker, self.val_loss_tracker]
def train_step(self, data):
inputs, _ = data
with tf.GradientTape() as tape:
anchor_embedding, positive_embedding, negative_embedding = self(inputs, training=True)
pos_dist = tf.reduce_sum(tf.square(anchor_embedding - positive_embedding), axis=1)
neg_dist = tf.reduce_sum(tf.square(anchor_embedding - negative_embedding), axis=1)
triplet_loss_value = tf.maximum(0.0, pos_dist - neg_dist + self.margin)
total_loss = tf.reduce_mean(triplet_loss_value)
trainable_vars = self.trainable_variables
gradients = tape.gradient(total_loss, trainable_vars)
self.optimizer.apply_gradients(zip(gradients, trainable_vars))
self.train_loss_tracker.update_state(total_loss)
return {"loss": self.train_loss_tracker.result()}
def test_step(self, data):
inputs, _ = data
anchor_embedding, positive_embedding, negative_embedding = self(inputs, training=False)
pos_dist = tf.reduce_sum(tf.square(anchor_embedding - positive_embedding), axis=1)
neg_dist = tf.reduce_sum(tf.square(anchor_embedding - negative_embedding), axis=1)
triplet_loss_value = tf.maximum(0.0, pos_dist - neg_dist + self.margin)
total_loss = tf.reduce_mean(triplet_loss_value)
self.val_loss_tracker.update_state(total_loss)
return {"loss": self.val_loss_tracker.result()}特に重要なポイントのみ触れておきます。
with tf.GradientTape() as tape:
anchor_embedding, positive_embedding, negative_embedding = self(inputs, training=True)
pos_dist = tf.reduce_sum(tf.square(anchor_embedding - positive_embedding), axis=1)
neg_dist = tf.reduce_sum(tf.square(anchor_embedding - negative_embedding), axis=1)
triplet_loss_value = tf.maximum(0.0, pos_dist - neg_dist + self.margin)
total_loss = tf.reduce_mean(triplet_loss_value)まず、train_stepはバッチ単位で実行されるようです。
よって、上記ブロック内では1つのバッチに関する損失値を計算していることになります。
anchor_embedding, positive_embedding, negative_embedding は、それぞれアンカー、ポジティブ、ネガティブのエンベディング結果をバッチ内で処理したトリプレット数だけ格納したtf.Tensorオブジェクトで、今回はバッチサイズが32、エンベディング結果は2048次元になるので、具体的な形状(shape)は (32, 2048) となるようです。
上記エンベディング結果に対してユークリッド距離の二乗を計算した結果が、pos_dist(アンカー・ポジティブ間)、 neg_dist(アンカーネガティブ間)であり、形状は (32, ) となります。
上記に対して “pos_dist – neg_dist + self.margin” を計算していますが、これは「neg_distがpos_distよりもmargin以上大きい(遠い)かどうか」を判定しており、遠ければマイナス、遠くなければプラスの結果になります。
それと0.0の大きな方を triplet_loss_value(バッチ内の各トリプレットごとの損失値) としています。
最後に、それらの平均値を算出し、これを total_loss(当該バッチの損失値)としています。
重要なのは、上記処理を “with tf.GradientTape() as tape:” ブロック内で行なっている点です。
このようにすることで、後述する勾配計算が簡単に行なえることになるようです。
trainable_vars = self.trainable_variables
gradients = tape.gradient(total_loss, trainable_vars)
self.optimizer.apply_gradients(zip(gradients, trainable_vars))trainable_vars は、当該モデルの訓練可能な全ての「重み」であり、先に触れたように今回は「conv5_block1_out」層以降のみ訓練可能としているので、それら層に属する「重み」と言うことになります。
gradients は total_loss を元に trainable_vars の各「重み」の変更量と方向(つまりは「勾配」)を算出したものです。
本来であれば、この部分は相当に面倒な計算(逆伝播)を行なうことになるはずなのですが、前述の「tf.GradientTape」を使用してエンベディング(順伝播)および損失計算に関する一連の操作を記録しておくことで、上記にあるように1行で勾配計算ができてしまうようです。
Python(Tensorflow)恐るべし。
で、最後に trainable_vars の各「重み」を gradients(勾配)によって更新しています。
この辺はオプティマイザ(self.optimizer)が行なうようです。
オプティマイザの指定に関しては後述しますが、今回も Adam を使用します。
全体の実行
今まで示した各種処理を実行することで、目的であるファインチューニングを行います。
import tensorflow as tf
from tensorflow import keras
import numpy as np
import os
import random
from glob import glob
from sklearn.model_selection import train_test_split
from lib.img_preprocess import train_preprocess, val_preprocess
from lib.triplet_generator import triplet_generator
from lib.build_encoder import build_encoder
from lib.triplet_model import TripletModel
# --- 定数の定義 ---
DATA_DIR = 'wine_labels'
IMAGE_SIZE = (224, 224)
BATCH_SIZE = 32
EPOCHS = 100
STEPS_PER_EPOCH_TRAIN = 100
STEPS_PER_EPOCH_VAL = STEPS_PER_EPOCH_TRAIN // 5
MARGIN = 1.0
LEARNING_RATE = 0.0000128
ES_PATIENCE = 40
LR_PATIENCE = 20
MIN_LR = 1e-6
os.environ['TF_CPP_MIN_LOG_LEVEL'] = '3' # FATAL messages only
image_paths = glob(os.path.join(DATA_DIR, '*.jpeg'))
labels = [os.path.basename(path).split('.')[0] for path in image_paths]
label_to_paths = {label: [path] for label, path in zip(labels, image_paths)}
train_labels, val_labels = train_test_split(labels, test_size=0.2, random_state=42)
train_augmentation_layers = [
keras.layers.RandomRotation(factor=0.02),
keras.layers.RandomZoom(height_factor=(-0.05, 0.05), width_factor=(-0.05, 0.05)),
keras.layers.RandomTranslation(
height_factor=0.1,
width_factor=0.1,
fill_mode='constant',
fill_value=0.0
)
]
train_dataset = tf.data.Dataset.from_generator(
lambda: triplet_generator({l: label_to_paths[l] for l in train_labels}, train_labels),
output_signature=(
tf.TensorSpec(shape=(), dtype=tf.string),
tf.TensorSpec(shape=(), dtype=tf.string),
tf.TensorSpec(shape=(), dtype=tf.string)
)
)
train_dataset = train_dataset.map(lambda a, p, n: (
(val_preprocess(a, IMAGE_SIZE),
train_preprocess(p, IMAGE_SIZE, train_augmentation_layers),
train_preprocess(n, IMAGE_SIZE, train_augmentation_layers)),
tf.constant(0.0)
), num_parallel_calls=tf.data.AUTOTUNE)
train_dataset = train_dataset.batch(BATCH_SIZE).prefetch(tf.data.AUTOTUNE)
train_dataset = train_dataset.take(STEPS_PER_EPOCH_TRAIN)
val_dataset = tf.data.Dataset.from_generator(
lambda: triplet_generator({l: label_to_paths[l] for l in val_labels}, val_labels),
output_signature=(
tf.TensorSpec(shape=(), dtype=tf.string),
tf.TensorSpec(shape=(), dtype=tf.string),
tf.TensorSpec(shape=(), dtype=tf.string)
)
)
val_dataset = val_dataset.map(lambda a, p, n: (
(val_preprocess(a, IMAGE_SIZE),
val_preprocess(p, IMAGE_SIZE),
val_preprocess(n, IMAGE_SIZE)),
tf.constant(0.0)
), num_parallel_calls=tf.data.AUTOTUNE)
val_dataset = val_dataset.batch(BATCH_SIZE).prefetch(tf.data.AUTOTUNE)
val_dataset = val_dataset.take(STEPS_PER_EPOCH_VAL)
encoder_model = build_encoder(IMAGE_SIZE)
triplet_model = TripletModel(encoder=encoder_model, margin=MARGIN)
triplet_model.compile(
optimizer=tf.keras.optimizers.Adam(learning_rate=LEARNING_RATE)
)
triplet_model.fit(
train_dataset,
epochs=EPOCHS,
validation_data=val_dataset,
callbacks=[
tf.keras.callbacks.EarlyStopping(monitor='val_loss',
patience=ES_PATIENCE,
restore_best_weights=True),
tf.keras.callbacks.ReduceLROnPlateau(monitor='val_loss',
factor=0.5,
patience=LR_PATIENCE,
min_lr=MIN_LR)
]
)
encoder_model.save('trained_wine_label_encoder.keras')ここも、ポイントになりそうな部分のみ触れておきます。
train_augmentation_layers = [
keras.layers.RandomRotation(factor=0.02),
keras.layers.RandomZoom(height_factor=(-0.05, 0.05), width_factor=(-0.05, 0.05)),
keras.layers.RandomTranslation(
height_factor=0.1,
width_factor=0.1,
fill_mode='constant',
fill_value=0.0
)
]先にデータ拡張処理(augment_image)に関して紹介しましたが、その際に、一部に関しては外部で用意した変換処理を使用する点に触れておきました。
上記がその変換処理で、「TensorFlow 2.x および Keras で提供される前処理レイヤー(Preprocessing Layer)の機能」らしいです。
実は本処理を augment_image 内に書くとエラーになるため上記のようにしているのですが、エラーの原因に関しては深く追求していません(「tf.data.Dataset.map」内に渡される関数は、内部でTensorFlowのグラフモードに変換され云々…と言うような説明をされたのですが、途中で迷子になりました)。
train_dataset = tf.data.Dataset.from_generator(
lambda: triplet_generator({l: label_to_paths[l] for l in train_labels}, train_labels),
output_signature=(
tf.TensorSpec(shape=(), dtype=tf.string),
tf.TensorSpec(shape=(), dtype=tf.string),
tf.TensorSpec(shape=(), dtype=tf.string)
)
)まず、tf.data.Dataset.from_generator は「Pythonの通常のジェネレータ関数(yieldを使用する関数)を、TensorFlowの tf.data.Dataset オブジェクトに変換するためのファクトリメソッド」とのことで、大雑把に言えば、triplet_generator関数によってtf.data.Dataset内の値を動的に生成するように設定しています。
output_signatureはジェネレータ(triplet_generator)が返す値の構造(形状とデータ型)を指定しています。
今回のケースでは、triplet_generator が返すのはアンカー、ポジティブ、ネガティブのパス(文字列)になります。
train_dataset = train_dataset.map(lambda a, p, n: (
(val_preprocess(a, IMAGE_SIZE),
train_preprocess(p, IMAGE_SIZE, train_augmentation_layers),
train_preprocess(n, IMAGE_SIZE, train_augmentation_layers)),
tf.constant(0.0)
), num_parallel_calls=tf.data.AUTOTUNE)tf.data.Dataset.map メソッドは、データセットの各要素に対して、指定された関数を適用し、変換された新しいデータセットを返すものです。
先の triplet_generator の出力は、あくまで各種画像のパスだったので、val_preprocess, train_preprocess によって画像の読み込みやデータ拡張(train_preprocessのみ)を行なっています。
なお、学習用データは “(学習対象となるデータ, 正解データ)” のような構造を持つようですが、今回のトリプレット損失学習では、損失は3つのエンベディング間の距離に基づいて計算されるため、正解データの部分は必要ありません。
よって、インタフェースの整合性を保つためのダミーデータとして、正解データ部分にはスカラー値0.0を持つ定数テンソルである「tf.constant(0.0)」を指定しているようです(単に0.0ではなく tf.constant(0.0) などと周りくどい書き方をしているのはデータ型の一貫性を考慮してのことらしいです)。
また、num_parallel_callsは、前述の変換を並列で実行する際の並列度(同時に実行する関数の呼び出し数)を制御するための設定とのことです。
「tf.data.AUTOTUNE」は「最適な並列度を自動的に決定する」ということのようで、要は「よしなに」と言うことですね。
train_dataset = train_dataset.batch(BATCH_SIZE).prefetch(tf.data.AUTOTUNE)
train_dataset = train_dataset.take(STEPS_PER_EPOCH_TRAIN)1行目ではバッチサイズを指定しています。
以前「バッチって良く分からん」と言うことで理解を放棄していましたので、今更ながら触れておくと、「重み更新の最小単位」と言った理解で良さそうです。
用意された学習用データセット全てに関して学習を1回実施することを意味する単位がepochですが、全てのデータに関してまとめて学習を実施する訳ではなく、小さなグループに分け、それぞれに対して学習を実施する(重みの更新を行なう)ようにしていて、このグループが「バッチ」です。
例えばデータセットが100点あって、バッチサイズが32だった場合は、1epochで4回(学習用データ数は32,32,32,4個)のバッチ処理(重み更新)が行われることになります。
上記を踏まえて2行目ですが、1epochで実行するバッチ数を指定しています。
先に触れたように、通常はデータセット数が決まっているので、バッチサイズが決まれば、1epochで何回のバッチ処理が行われるかが確定します。
しかし、今回実装した triplet_generator は無限にデータセットを提供し続けるので、逆に1epochで何回のバッチ処理を行なうかを指定しています。
今回はSTEPS_PER_EPOCH_TRAINを100としているので、100バッチ処理し終わったら1epoch終了になります。
val_dataset = val_dataset.map(lambda a, p, n: (
(val_preprocess(a, IMAGE_SIZE),
val_preprocess(p, IMAGE_SIZE),
val_preprocess(n, IMAGE_SIZE)),
tf.constant(0.0)
), num_parallel_calls=tf.data.AUTOTUNE)学習用データと同様に評価用データの読み込みを行なっています。
注意が必要なのは、アンカーとポジティブの両方に val_preprocess を使用している点です。
val_preprocess はデータ拡張を行わないので、アンカーとポジティブのエンベディング結果は全く同じになり、当然ながら両者の距離は0になります。
つまり、評価時に算出されるval_lossは、アンカーとネガティブの距離(正確にはユークリッド距離の二乗)と margin との比較のみとなり、アンカーとポジティブの距離は考慮されません。
個人的には評価用のポジティブにも train_preprocess を適用して良いのではないかと思ったのですが、「データ拡張はモデルの汎化能力を向上させる目的でトレーニング時のみ使用すべきテクニックであり、一貫した評価基準であるべきval_lossの計算に用いるデータに適用すべきではない」とのGemini先生のご指導がありましたので、現状は上記のようになっています。
本来であれば、アンカーとポジティブは(同じラベルを写した)別画像を使用すべきであり、アンカーと同じ画像にデータ拡張を行なってポジティブを生成するのは苦肉の策であるため、val_lossの計算にも前述のような不完全さが生じるのは仕方がないことかもしれません。
encoder_model = build_encoder(IMAGE_SIZE)
triplet_model = TripletModel(encoder=encoder_model, margin=MARGIN)
triplet_model.compile(
optimizer=tf.keras.optimizers.Adam(learning_rate=LEARNING_RATE)
)先に示した、build_encoder, TripletModel を使用して、学習用モデルを生成しています。
margin は train_step の説明で触れたように、ポジティブとネガティブの距離の差をどの程度に期待するかを示す重要なハイパーパラメータです。
margin が小さいと、エンベディング結果でポジティブ(同じもの)とネガティブ(違うもの)の差が小さくなり、本来の目的である両者の区別が難しくなります。
margin が大きいと、学習自体が難しくなるようです。
と言うことで、一般的には margin は0.1〜1.0くらいにするようですので、今回は最大限の効果を期待して1.0にしています。
オプティマイザにはAdamを指定していますが、セマンティックセグメンテーションの際にも重要だった「学習率」に関しては操作できるようにしています。
triplet_model.fit(
train_dataset,
epochs=EPOCHS,
validation_data=val_dataset,
callbacks=[
tf.keras.callbacks.EarlyStopping(monitor='val_loss',
patience=ES_PATIENCE,
restore_best_weights=True),
tf.keras.callbacks.ReduceLROnPlateau(monitor='val_loss',
factor=0.5,
patience=LR_PATIENCE,
min_lr=MIN_LR)
]
)学習の実行に関してもセマンティックセグメンテーションの時と同様ですが、ReduceLROnPlateau に加えて EarlyStopping を指定しています。
これは指定した指標が一定期間改善しなかったら学習を中断するというものです。
monitor は基準とする指標を指定しています。
patience は改善がない期間(epoch)を指定するもので、ここで指定したepochの間にmonitorで指定した指標が改善しなければ学習を中断します。
restore_best_weights はmonitorで指定した指標が最も良かったepochの重みを採用するかどうかを指定するもので、Trueにすることで、当該学習全般を通して最もmonitor(今回はval_loss)が良かった(小さかった)学習結果が残されます。
ファインチューニングの実行
実際にファインチューニングを実行してみました。
学習状況は以下の通り。
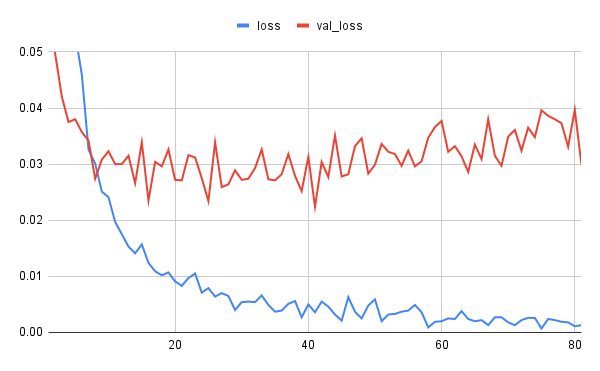
lossの方は何となく減衰傾向にあるようですが、val_lossの方は怪しいですね。
val_lossが最小となった状況は以下の通りです。
| epoch | 41 |
| loss | 0.0036 |
| val_loss | 0.0224 |
41epoch以降val_lossが改善されなかったため、ES_PATIENCEで指定した40epoch経過した81epochを以て学習を早期終了しています。
コサイン距離の確認
「ラベル画像のエンベディング」と同様にコサイン距離の確認を行なってみます。
| 11 | 12 | 13 | 14 | 15 | 21 | 22 | 23 | 24 | 25 | 31 | 32 | 33 | 34 | 35 | 41 | 42 | 43 | 44 | 45 | |
| 11 | – | 0 | 0 | 0 | 0 | 5 | 5 | 5 | 5 | 5 | 4 | 4 | 4 | 3 | 4 | 5 | 5 | 5 | 5 | 5 |
| 12 | – | 0 | 0 | 0 | 5 | 5 | 6 | 5 | 5 | 4 | 4 | 4 | 4 | 4 | 5 | 5 | 5 | 5 | 5 | |
| 13 | – | 0 | 0 | 5 | 5 | 5 | 5 | 5 | 4 | 4 | 4 | 3 | 3 | 5 | 5 | 5 | 5 | 5 | ||
| 14 | – | 0 | 5 | 6 | 6 | 5 | 5 | 4 | 4 | 4 | 3 | 4 | 5 | 5 | 5 | 5 | 5 | |||
| 15 | – | 5 | 5 | 6 | 5 | 5 | 4 | 4 | 4 | 4 | 3 | 5 | 5 | 5 | 5 | 5 | ||||
| 21 | – | 0 | 0 | 0 | 0 | 4 | 4 | 4 | 4 | 5 | 4 | 4 | 4 | 4 | 4 | |||||
| 22 | – | 0 | 0 | 0 | 4 | 4 | 5 | 4 | 5 | 4 | 4 | 4 | 4 | 4 | ||||||
| 23 | – | 1 | 1 | 4 | 4 | 4 | 4 | 5 | 4 | 4 | 4 | 4 | 4 | |||||||
| 24 | – | 0 | 4 | 4 | 4 | 4 | 5 | 4 | 4 | 4 | 3 | 4 | ||||||||
| 25 | – | 4 | 4 | 4 | 4 | 4 | 4 | 4 | 4 | 3 | 4 | |||||||||
| 31 | – | 0 | 1 | 0 | 1 | 4 | 4 | 4 | 4 | 4 | ||||||||||
| 32 | – | 1 | 0 | 2 | 4 | 4 | 4 | 4 | 4 | |||||||||||
| 33 | – | 1 | 1 | 4 | 4 | 4 | 4 | 3 | ||||||||||||
| 34 | – | 1 | 4 | 4 | 4 | 4 | 4 | |||||||||||||
| 35 | – | 4 | 4 | 4 | 4 | 3 | ||||||||||||||
| 41 | – | 0 | 0 | 0 | 0 | |||||||||||||||
| 42 | – | 0 | 0 | 0 | ||||||||||||||||
| 43 | – | 0 | 0 | |||||||||||||||||
| 44 | – | 0 | ||||||||||||||||||
| 45 | – |
ResNet50オリジナル(ファインチューニング未実施)の結果と比較して、ポジティブ(同じラベル)との距離に関しては1つのケース(32-35)を除いて0.2未満に納まっています。
0.2を超えたケースに関しても、後述するように際どい値(0.2044…)で、もう少しセグメンテーションの精度が良かったり、ファインチューニングがうまく行けば、0.2未満に納まったかもしれません。
一方で、ネガティブ(別のラベル)との距離に関しては0.3未満のケースがなくなり、90%以上は0.4以上です。
もう少し細かく見てみましょう。
オリジナル、チューニング後それぞれのポジティブ(pos)、ネガティブ(neg)に関して、0.05単位で区切った各範囲に何件のケースが存在するかを整理してみました。
| オリジナル pos | オリジナル neg | チューニング後 pos | チューニング後 neg | |
| 0.0 – 0.05 | 12 | 0 | 7 | 0 |
| 0.05 – 0.1 | 21 | 0 | 24 | 0 |
| 0.1 – 0.15 | 4 | 0 | 5 | 0 |
| 0.15 – 0.2 | 1 | 0 | 3 | 0 |
| 0.2 – 0.25 | 2 | 0 | 1 | 0 |
| 0.25 – 0.3 | 0 | 11 | 0 | 0 |
| 0.3 – 0.35 | 0 | 36 | 0 | 0 |
| 0.35 -0.4 | 0 | 42 | 0 | 9 |
| 0.4 – 0.45 | 0 | 10 | 0 | 43 |
| 0.45 – 0.5 | 0 | 39 | 0 | 43 |
| 0.5 – 0.55 | 0 | 12 | 0 | 24 |
| 0.55 – 0.6 | 0 | 0 | 0 | 27 |
| 0.6 – 0.65 | 0 | 0 | 0 | 4 |
直感的に状況を把握できるようグラフ化してみます。
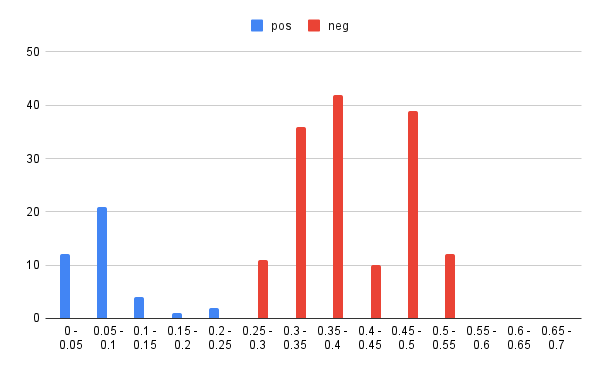
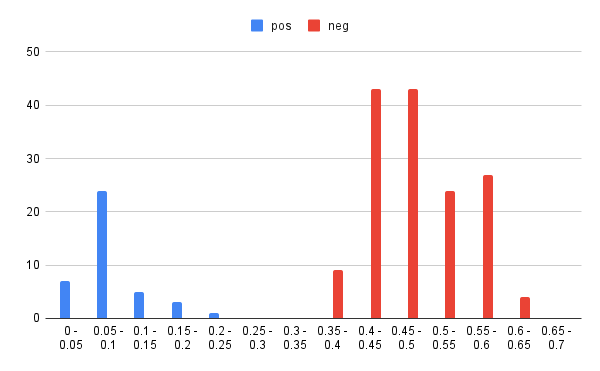
ファインチューニング後の方が、より二極化が進んでいることが分かります。
ネガティブの方が全体的に0.1程度後ろにずれたような印象です。
0.25から0.35辺りに全くデータが存在しない区間があるので、もう少し紛らわしい(似ている)ラベル相互の区別に際しても、混同する可能性が軽減しているとの期待が持てます。
前回同様、ポイントになりそうな距離を具体的に見てみましょう。
| オリジナル | チューニング後 | |
| ポジティブ最小距離 | 0.024057833544022023(42-43) | 0.027953190186555288(41-43) |
| ポジティブ最大距離 | 0.2340515825328603(34-35) | 0.20441832463412357(32-35) |
| ポジティブ最大距離(35を除く) | 0.12959717844480667(32-33) | 0.16018944255546785(32-33) |
| ネガティブ最小距離 | 0.2601928593368079(24-44) | 0.37765589293100565(35-45) |
ポジティブに関する各種距離が大きく変わっていないのに対し、ネガティブに関する最小距離が0.1以上大きくなっています。
この点は、先に示したグラフの印象と一致します。
なお、ネガティブ最小距離となったケースは以下です。
| 35 | 45 |
 |  |
白地に黒文字や黒いイラストが書かれて(描かれて)いるという点で見れば、オリジナルでネガティブ最小距離となった以下のケースよりは「似ている」と言って良いかもです。
| 24 | 44 |
 |  |
ただ、個人的な感想としては、上記くらいの違いがあれば、やはり0.5以上の距離になることを期待したくなります。
まとめ
とりあえず、オリジナルのResNet50(+ImageNet)に対してファインチューニングを実施し、ワインラベルの識別により適合したエンベディング用モデルの生成ができることは確認できました。
ただ、学習の推移(val_lossの減衰傾向)はかなり怪しいですし、エンベディングの精度の向上(ポジティブとネガティブの差の拡大)に関しても、もう少し頑張ってみたいところです。
最優先課題として、学習用データを充実させること(アンカーとポジティブを別画像にする等)を再三Gemini先生から指摘されていますが、簡単に手を出しにくい部分ではあります。
一方で、今回の方式に関して、既に現時点で2つの改善点が分かっています。
- 勾配計算にユークリッド距離を使用している点
ワインラベルの識別と言うテーマに対してはコサイン距離の方が適しており、最終的なベクトル検索時にもコサイン距離を利用する予定だが、現状の勾配計算にはユークリッド距離を使用している。
学習時と運用時では同じ距離を使用すべき。 - ネガティブをランダムに抽出している点
学習効率・汎化性能の向上のためにはネガティブはアンカーと似たもの(ハードネガティブと呼ぶらしい)を使用した方が効果的。
よって、ネガティブをランダムに選ぶのではなく、アンカーと距離の近いものを事前に確認しておき、これらを使用すべき。
次回は上記に関してチャレンジしたいと思います。