{kind=link}
「ラベル画像のトリミング(2)」では、TensorFlow/KerasでのU-Netモデル構築から学習、ならびにセグメンテーションの実行に関する処理を実装しました。
今回は上記処理を実際に動かしてみた結果に関して投稿したいと思います。
なお、学習に用いる画像データは100点で、それらを学習用80点と評価用20点に使い分けています(この辺はcreate_tf_dataset内の処理で自動的に行なっています)。
検証1
ともかく一回学習およびセグメンテーションを実行してみましょう。
ネット情報等からepoch数は数百程度は必要っぽいですが、実際に動かしてみたところ1epochの所要時間が約5分(最新のMac mini M4チップ)だったので、とりあえず200epochを目標としました。
また、モデルの学習ロジックにおいては既に学習済みのモデルに対する追加学習が可能なように実装していますので、途中経過の確認もできるよう、1回の学習を10epochとし、学習終了ごとにセグメンテーションを実行して結果を残すようにします。
これを20回繰り返すことで、計200epochの学習を実施します。
その結果ですが、以下に代表的な2つ画像に関する学習状況をまとめてみました。
画像1は期待外れの例として、画像2は比較的良い感じになった例です。
最初に元画像とアノテーション結果を載せておきました。
前述したように10epoch学習するごとにセグメンテーションを実施しましたので、その結果を一覧として載せてあります。
本来であれはセグメンテーション結果がアノテーション結果に極めて近い状態になることを期待したいところですが、実際の結果としては微妙なものになっています。
なお、一覧の最後にそれぞれの画像に関してヒストグラム平坦化を行わなかった場合と、さらにそれを閾値0.5で二値化した場合のセグメンテーション結果も載せておきました(使用したのは200epochの学習済みモデル)。
本来、ヒストグラム平坦化は必要ない処理だったのですが、数十epoch程度の学習段階では結果が白黒のいずれか一方に偏る場合が多かったので、目視による学習状況の確認がしやすいように実施していました。
しかし、上記のように200epoch段階になると(結果が期待通りか否かは別にして)白黒のメリハリが非常に明確になるため、ヒストグラム平坦化は必要なさそうです。
lossは学習用データセットに対する損失関数の値、val_lossは評価用データセットに対する損失関数の値です。
これらはmodel.fitの実行時にリアルタイムに表示されます。
| 画像1 | 画像2 | |||
| 元画像 |  |  | ||
| マスク画像 |  |  | ||
| epoch | 画像1 | 画像2 | loss | val_loss |
| 10 |  | 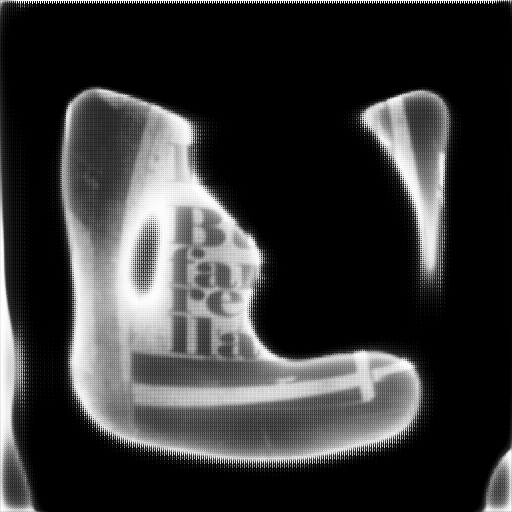 | 0.2455 | 0.8839 |
| 20 |  |  | 0.1861 | 0.3666 |
| 30 |  |  | 0.1535 | 0.3185 |
| 40 |  |  | 0.1292 | 0.2985 |
| 50 |  |  | 0.1173 | 0.2842 |
| 60 |  |  | 0.0888 | 0.2698 |
| 70 |  |  | 0.0976 | 0.2732 |
| 80 |  |  | 0.0670 | 0.2620 |
| 90 |  |  | 0.0741 | 0.2473 |
| 100 |  |  | 0.0615 | 0.1849 |
| 110 |  |  | 0.0579 | 0.1398 |
| 120 |  |  | 0.0466 | 0.1560 |
| 130 |  |  | 0.0460 | 0.1343 |
| 140 |  |  | 0.0444 | 0.1642 |
| 150 |  |  | 0.0387 | 0.1405 |
| 160 |  |  | 0.0479 | 0.1412 |
| 170 |  | 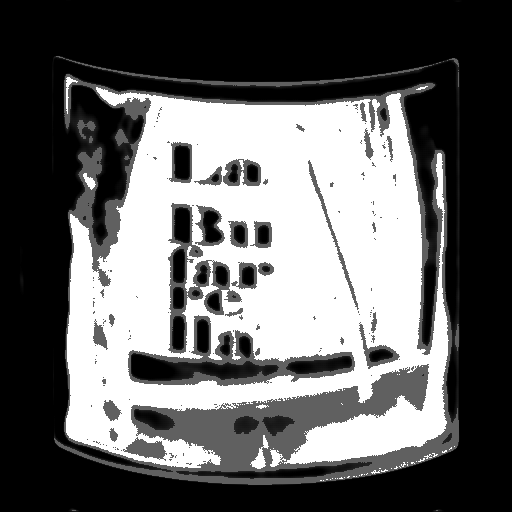 | 0.0547 | 0.1870 |
| 180 |  |  | 0.0437 | 0.1968 |
| 190 | 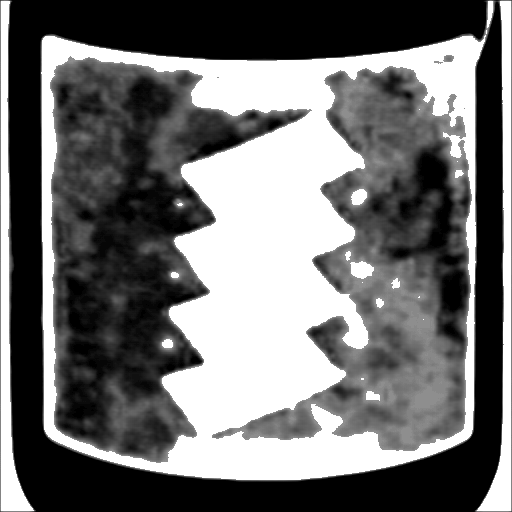 |  | 0.0423 | 0.1240 |
| 200 |  |  | 0.0365 | 0.1608 |
| 平坦化なし |  |  | ||
| 二値化 (0.5) |  |  |
最終的な結果(200epoch)ですが、画像1に関してはラベルに描かれた絵柄や文字の存在がセグメンテーション結果に反映されてしまっています。
一方、画像2に関してはラベル部分が白く塗り潰されているので、この点では期待した結果が得られたと言えます。
ただ、両方の画像に共通して言えることは、黒く塗り潰された部分はあくまでワインボトルの部分であって、ボトルの背景に当たる部分は白くなってしまっています。
よって、画像2に関しても全てが期待通りという訳ではありません。
学習過程を見ると、100epoch辺りから急に最終結果に近い内容になり、120epoch以降は大きな変化がないのですが、170epochの段階で突然傾向が変わり、その後元に戻っています。
170epochの内容を見ると、画像2に関してはラベル内の絵柄や文字が結果に反映されてしまっているので、前後の結果と比較して悪い内容に見えますが、逆に画像1に関してラベル部分全体を白寄り(ラベルの可能性高)と判断できているので、こちらに関しては良い内容と言えます。
さらに、特筆すべきはラベル以外の部分(ボトル以外の部分も含めて)の認識が両画像ともに正しくできている点です。
ラベル部分とそれ以外の部分を区別するという本来の目的から言えば、170epochの内容はかなり理想に近いと言えるかもしれません。
それが以降で元に戻ってしまったのは残念です。
損失関数の値の遷移を見ると、lossの遷移に関しては、120epoch辺りまでは概ね順調に小さくなっていき、その後は緩やかに増えたり減ったりしています。
val_lossの遷移に関しても同様で、100epoch辺りまでは小さくなっていき、その後は増減を繰り替えしています。
印象としては100〜120epoch辺りで収束してしまっているように思われます(前述したように170epoch時のように突然変異的な状況が発生するケースもあるようですが)。
また、lossとval_lossの差が大きいので、過学習の傾向も見られるようです。
総じて、ある程度は期待した方向に進んだものの、精度に関しては不十分と言った学習結果でしょう。
検証2
検証1では10epochずつに分けて、計20回の学習を実施しています。
これは既に学習済みのモデルに対して追加学習が実行できるような仕組みになっているために実現できたことですが、この学習の一旦の終了(中断)と再開においては、本当に以前の学習結果を適切に継承できているかが不明確でした(実装に関しては、ほとんどGemini先生任せなので)。
また、同じ学習データを使用し、同じepoch数の学習を実施したモデルでも、別々に学習したモデルではセグメンテーション結果が微妙に違ってくるということも今までの試行錯誤である程度理解できていました。
ということで、検証1の結果(「10epoch*20」と記載します)に対して、200epochを一度にまとめて学習するパターンを2回実行してみて(それぞれ「200epoch(1)」「200epoch(2)」と記載します)、その違いを確認してみたいと思います。
こちらも、代表的なケースをいくつか載せてみました。
| 元画像 | 200epoch(1) | 200epoch(2) | 10epoch*20 | |
| 1 |  |  |  |  |
| 2 |  |  |  |  |
| 3 |  |  |  |  |
| 4 |  |  |  |  |
| 5 |  |  |  |  |
| 6 |  |  |  |  |
1,2に関しては、元画像が類似した内容になっています(ぱっと見で違いとして認識できるのはラベルの色くらい)。
上記のように類似性の高い画像であるにも関わらず、セグメンテーション結果は意外な内容になっています。
1に関しては「200epoch(2)」が比較的良く、「200epoch(1)」「10epoch*20」の方はラベル内の絵柄がかなり残ってしまっています。
一方、2に関しては全般的にラベルの絵柄が残っていますが、中でも「200epoch(2)」が最も悪い状態と言えます。
3に関しては「200epoch(1)」「10epoch*20」と「200epoch(2)」でかなり差があります。
「200epoch(2)」は理想に近い内容ですが、「200epoch(1)」「10epoch*20」はほとんど元画像のまま(ラベルとボトルの境界もあまり認識できていない状態)です。
上記3件を見ると「200epoch(1)」「10epoch*20」の結果は類似性が高く、「200epoch(2)」のみが(良くも悪くも)違う印象ですが、4に関しては三者三様です。
また、全体的に見ると「200epoch(2)」が比較的良い結果を残しているようですが、5に関しては「200epoch(1)」が良く、6に関しては「10epoch*20」が良いので、単純に優劣を決められるものでもなさそうです。
上記より、少なくとも200epochの学習をまとめて実施した場合と、小さなepoch数に分割して実施した場合での違いはあまり考える必要はなさそうです。
一方で、同じ200epochでも学習結果には結構な違いがあります。
これだけを見ると学習の余地が残っているようにも思われ、もっと学習を進める(epoch数を増やす)ことで改善することを期待したくなりますが、検証1で触れたようにloss、val_lossの遷移を見ると、逆にこれ以上epoch数を増やしてもあまり改善は望めないような印象もあります。
まとめ
上記のように、現在のモデルの状況は「それっぽいセグメンテーションを実施できるが、精度は不十分」と言ったものです。
単純にepoch数を増やすことでの改善も期待できなくはないですが、可能性は高くない印象です。
と言うことで、改めて現在の方針に関する問題点を考えてみました。
- 学習に使用している画像セット数が少ない
- 学習に使用している画像におけるラベル部分の占有面積が大きすぎる
- モデルの構造に問題がある
- 学習時に指定しているハイパーパラメータが不適切(最適でない)
3,4に関しては素人が手を出すには難易度が高そうなので、一旦は保留にしたいと思います。
実のところ、問題点の本命と思っているのは2の件です。
弊社ECサイトで使用している画像をそのまま流用したもので、学習用に考えられたものではないため、認識させたい対象のラベル部分が画像の大半を占めているものが多いです。
Gemini先生曰く、セマンティックセグメンテーションの学習データとしては、認識させたい対象物の占有面積はあまり大きくない方が良いようです。
例えば、全体の面積の90%が対象物で占められる画像に対しては、とりあえず全体を白(対象物)とするだけで90%の正解率になってしまいます。
このような画像ばかりで学習していては、上記のような山勘的な判断でも精度の高い(lossの少ない)判断と錯覚されても仕方ありません。
検証1の途中経過でも、前半の方は全体白の結果がいくつか見られますし。
と言うことで、改めて学習用画像として、ラベル部分の占有面積が小さい画像を撮影してもらっています。
ワインの在庫が手元にはないもので。
I君、お手数をお掛けします (_0_)
数も現在の100点から200点に増やそうとしていますので、このデータでの成果に期待です。