{kind=link}
こんにちは。
「Today I Learned(今日学んだこと)」を記録するTIL、7月は社内のAI活用が本格的に動き出しました。グラボが新しすぎ問題に遭遇したり、巨大なモデルを無理やり動かしてみたり。
セルフホスト自体は特に難しいことはなくTILに書くほどでもなかったので、今回はDifyとComfyUIの活用を中心に紹介します。
セルフホストしたアプリケーション群
6月に新マシンが納品されてから準備を進めていた各種アプリケーションを、7月に入って社内公開しました。導入したのは以下のツール:
- Dify: ノーコードでAIアプリケーションを構築できるプラットフォーム。チャットボットやワークフローを簡単に作成
- n8n: ワークフロー自動化ツール。APIの連携やタスクの自動化に活用
- ComfyUI: ノードベースの画像生成UI。画像生成パイプラインを柔軟にカスタマイズ
- Ollama: ローカルLLMを簡単に実行できるツール。様々なオープンソースモデルに対応
- Open WebUI: ChatGPTライクなUIでローカルLLMとやり取りできるWebアプリ
- Firecrawl: Webページをクロールしてマークダウンに変換するツール。RAG用のデータ収集に便利
これらを組み合わせることで、社内で完結するAI活用環境を構築できました。
2025年7月のピックアップ
画像生成環境の構築 – Stable DiffusionからComfyUIへ (07/02〜07/04)
社内で画像生成環境を整備することになり、まずは定番のStable Diffusion WebUIから試しました。ところが、新しいマシンに搭載されたRTX 5060 Tiが新しすぎて、CUDAのバージョン関係でエラーが発生。この手のCUDAバージョン問題には、その後も何度か遭遇することになります。
(1)Stability Matrixで解決 (07/02)
いろいろ試行錯誤した結果、Stability MatrixでStable Diffusion WebUI Forge Classicを入れてみたら無事動作しました。ひとまず画像生成ができるようになったものの、いくつか問題点が:
- 複数人で共有することを前提にしていないツールがほとんど。社内で共有するには不便
- Stability Matrix自体はデスクトップアプリで手動起動が必要
個人利用なら問題ないけど、社内の誰でも使えるようにしたかったので、別の方法を探してみることに。
(2)ComfyUIへの移行とDocker化 (07/04)
DifyからSD WebUIに生成のリクエストを出せるようにはなったものの、あまり細かい調整ができなくて不便でした。そこで基盤をComfyUIに変更、起動方法もStability MatrixからDockerに切り替えてみました。
これによりデスクトップ環境不要で自動起動できるようになりました🙆♂️
最初はノードベースのUIに戸惑いましたが、慣れればSD WebUIよりも柔軟で強力。
一つ困ったのは、生成後にVRAMからモデルがなかなかアンロードされない問題。OllamaなどVRAMを使う他のサービスと併用するとメモリが足りなくなります。調べてみると、強制的にアンロードするノードがあったので、これをワークフローに挟んで解決しました。
ComfyUI-Unload-Model: https://github.com/SeanScripts/ComfyUI-Unload-Model
APIでDifyから呼び出す時にはこのノードを使い、手動操作時は別でアンロードボタンがあるのでそちらを使う運用に。
(3)DifyからComfyUIを使う (07/04)
ComfyUIで作ったワークフローをJSONで保存し、Dify側の専用ブロックにJSONを貼り付けて実行する仕組みを構築しました。プロンプト等はJSONの書き換えで対応します。
そのまま文字列を挿入するとJSONのフォーマットエラーになるので、JavaScriptコードブロックで必要なプロパティを書き換える方式にしました。
これでComfyUIを直接触らなくても、Difyチャットボットから画像生成ができるようになりました。プロンプトはLLMで生成するので、ユーザーは日本語でリクエストを送るだけ。解像度は数パターン用意して選択肢から選べるようにしました。
ComfyUIに詳しくない社内ユーザーも気軽に画像生成を使えるようになりました。
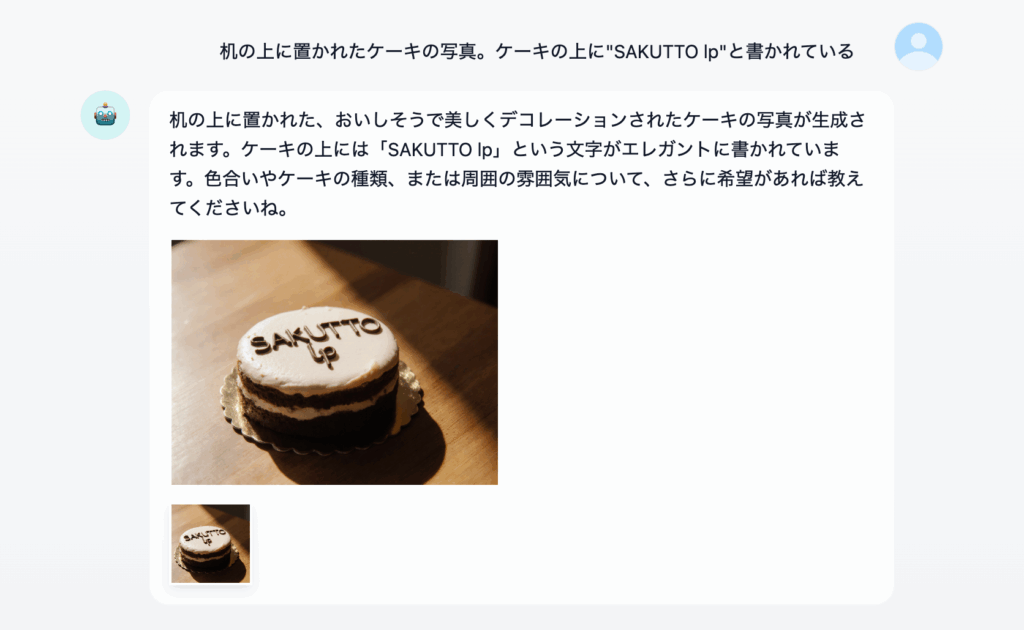
Llama 4 ScoutでMoEを試す (07/09)
MoE(Mixture of Experts)というアーキテクチャを知って、ぜひ試してみたくなりました。調べてみたらLlama 4 ScoutがOllamaで使えることが分かり、早速挑戦。
Llama 4 Scout: https://ollama.com/library/llama4:17b-scout-16e-instruct-q4_K_M
“109B parameter MoE model with 17B active parameters”
MoEは大量のパラメータを持ちながら、入力ごとに一部の「専門家」ネットワークだけを使うことで計算コストを削減する手法。109Bという巨大なパラメータ数でも、実際に使われるのは17B分だけというのが面白いところです。
結果:”一応”動きました。ただし:
- 生成速度はもっさり(response_token/s: 3.94)
- VRAMは使ってるけどGPU負荷が上がらない。多分VRAM不足でCPU処理に回ってる
- RAM上にも50GBぐらい展開するため、初期読み込みにかなり時間がかかる
頑張って動かした割にはあまり賢くない印象。サポート外の日本語でやり取りしている影響もありそうですけど。今のところ、実用的にはGemma 3 12Bが一番バランスが良くて、社内でもメインで使用しています。
完全ローカル化のための日本語埋め込みモデル PLaMo-Embedding-1B の導入 (07/17)
社内ドキュメントを完全にローカルで扱えるようにするため、日本語に強い埋め込みモデルをローカルで動かすことに。選んだのは Preferred Networks の PLaMo-Embedding-1B です。
PLaMo-Embedding-1B: https://huggingface.co/pfnet/plamo-embedding-1b
(1)Text Embeddings Inference (TEI) での失敗
最初はHugging FaceのTEIを使おうとしましたが、二つの問題に直面:
- PLaMo-Embedding-1Bには
tokenizer.jsonがなくて利用できない - TEIが利用しているCUDAのバージョンが古く、RTX 5060 Tiで GPUが使えない(またCUDAバージョン問題!)
(2)自前のAPIサーバー実装
そこでFastAPIでTEIのインターフェイスを真似たエンドポイントを実装しました。必要だったのは /embed と /info だけだったので、わりと簡単でした。DifyからはTEIのモデルプロバイダーとして設定すれば、そのまま利用可能。
GPUも使えるようになりましたが、起動中はずっと2GB程度のVRAMを占有し続けるのが気になりました。貴重なVRAMなので最終的にCPU処理に切り替え。RAGの検索に使う程度なら十分な速度で、実用上問題ありません。
これでローカルLLMと組み合わせて、社内ドキュメントを完全に外部APIに頼らずに処理できる環境が整いました。機密情報を含むドキュメントも安心して扱えるようになったのは大きな前進です。
Difyナレッジへの参考元リンク表示機能の追加 (07/18)
同僚が作ってくれた社内ドキュメント検索チャットボットに、参考元のドキュメントへのリンクを表示する機能を追加しました。
ナレッジに取り込んだドキュメントから回答するのは良いけど、やっぱり元のドキュメントを確認したいと思っていたので、Difyのメタデータ機能を活用することに:
- ナレッジ登録時にタイトルやURLなどの情報をメタデータとして登録
- ワークフローの知識検索ブロックの出力に含まれる
metadataを活用 - LLMへセグメント内容と一緒にメタデータも整形して渡す
回答フォーマットを調整すれば、参考元ドキュメントへのリンクを含めた回答が生成されます。ナレッジの登録はDifyのAPIを使って自動化しており、メタデータ登録もAPI経由で一括処理しています。
LLMによる検索クエリ最適化で賢い検索 (07/23)
Difyのワークフローで、検索の精度を上げるための工夫を実装しました。この手法はベクトル検索に限らず、Web検索など様々な用途に応用できそうです。
従来のベーシックなワークフローでは、ユーザーの入力をそのまま知識検索ブロックへ渡していました。これだと二つの問題があり:
- 余計な文字列を含んでベクトル検索してしまうため精度が落ちる
- RAGの結果はメモリに含まれないため、続きの検索ができない(「それのURLは?」のような質問に対応できない)
知識検索ブロックの前段階に検索クエリ生成LLMブロックを追加することで解決:
指示:
ユーザーが欲している情報を見つけるための検索用のクエリーを作成してください。
会話から質問の内容を把握し、**5語まで**検索クエリーのみを出力しダブルクォーテーション等の記号は用いないでください。
続きの会話だと思われる場合は、履歴から前の質問を確認して想定されるクエリーを作成すること。
これにより:
- ユーザーの入力から適切な単語を拾って検索用テキストに変換
- メモリが有効なので、前の会話も参考に検索クエリを生成
- 「それ」「さっきの」などの指示語も適切に解釈
検索精度が大幅に向上し、より自然な対話が可能になりました。
おわり
7月はセルフホストでAI関連ツールを社内公開して、誰でも使える環境が整いました。
アプリケーションで使うAIはローカルの他にOpenAIとGeminiも使っていますが、従量課金のAPIがどのくらい利用されているのかが分かりにくいのが悩みどころ。Cloudflare AI Gatewayを使ってみてもいいかもしれません。